全球主机交流论坛
标题:
小说精品屋plus的爬虫规则
[打印本页]
作者:
mzh
时间:
2020-5-17 12:08
标题:
小说精品屋plus的爬虫规则
本帖最后由 mzh 于 2020-5-17 12:17 编辑
首先非常感觉201206030大佬的程序,还得请大佬看看有哪里说的不对
1.爬虫站点的选择
选择目录列表为以固定前缀+分类数字+列表标号为目录的站
例如:
http://www.biquge.info/list/2_3.html 这种是好的
https://www.farpop.com/list1_2/ 或者这种,虽然没有明显的分页按钮,但是改地址可以的
https://www.230book.com/dushixiaoshuo/3_4.html 这种第一级前缀不固定不符合当前爬虫规则,不选
https://www.xbiquge.cc/xiuzhenxiaoshuo/ 这种站没有目录遍历的功能,而且改地址不可以的,不选
2.规则的设置
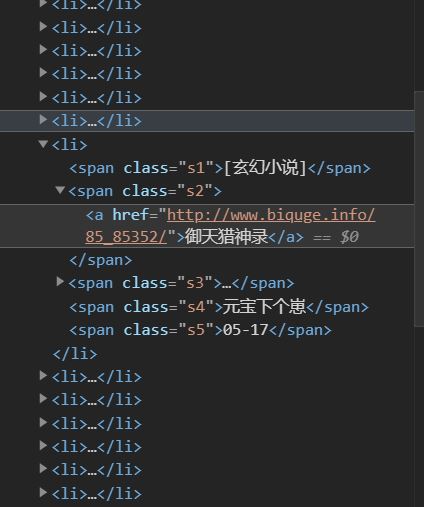
其实核心原则只有一个,就是F12查源码
依旧以http://www.biquge.info/list/2_3.html为例,按下F12
在右框element标签下选择小箭头,点击网页中的小说名字
能看到类似这样的界面
这里是列表页,有很多小说的链接地址,对应着爬虫设置中的“列表页小说ID正则表达式”
额,到这里就出现问题了,85_85352这个字符串没法用\d+表示
真的要表示得用这个href="http://www.biquge.info/(\d+_\d+)/
(此处可能没法爬取,我没看源码)
所有最好还是多找找有没有能用一个\d+就表示出来的站
我暂时除了示例的http://www.xdingdiann.com/还没看到其他的
以此类推,可以全部依靠F12查源码的方式填入爬虫源信息的对于表格里
或者
对着爬虫源信息填写表格的示例,依次按F12找对应的网址,看其中的哪个部分出现了和示例匹配字符串。这样一步一步理解就好了
但是真的,源站不好找啊
作者:
guonning2000
时间:
2020-5-17 12:10
好的源站太难,绝大分都是采集
作者:
mzh
时间:
2020-5-17 12:17
guonning2000 发表于 2020-5-17 12:10
好的源站太难,绝大分都是采集
太难了,我放弃了。不爬了
欢迎光临 全球主机交流论坛 (https://443502.xyz/)
Powered by Discuz! X3.4